
|
Brown University |
Brown University |
Adobe Research |
|
Adobe Research |
Brown University |
|
|
|
| Do vision-language models (VLMs) pre-trained to caption an image of a "durian" learn visual concepts such as "brown" (color) and "spiky" (texture) at the same time? We aim to answer this question as visual concepts learned "for free" would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. "spiky" as opposed to "spiky durian"), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models will be publicly released. |
|
|
|
Previous works demonstrated that concept-augmented prompts to improve the image recognition, which seemingly suggests that VLMs learn these concepts. However, we demonstrate that these concepts cannot provide conclusive evidence since certain "shortcuts" might bias the recognition results. When the category name is removed from the prompt (second column), the retrieved concepts are either non-visual or incorrect. We attribute this to the category name bias (third column), as the correct category can be retrieved by CLIP even when the paired descriptions are randomly shuffled and thus irrelevant. |
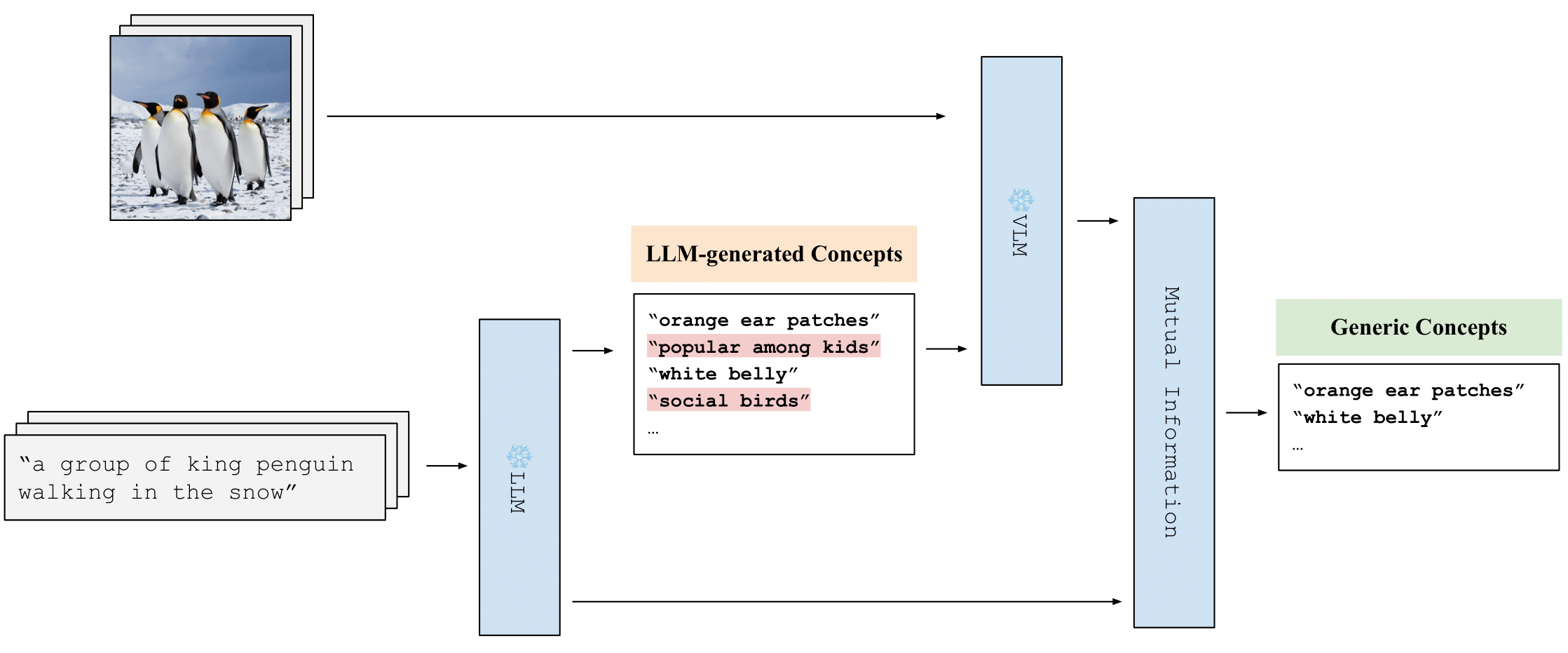 |
| We propose a new concept discovery strategy to eliminate the shortcuts and utilize both visual and language information, in order to properly investigate the concepts in pre-trained VLMs. We first use a large and diverse image captioning dataset~\cite{sharma2018conceptual} as a source of objects to discover diverse and thorough visual concepts shared by multiple objects. We then rank and select the visual concepts based on multimodal information: Given a collection of images and their text descriptions, we prefer the visual concepts that can be both reliably recognized from the images (e.g., with a pre-trained VLM), and deemed as suitable descriptions based on the text descriptions (e.g., according to the prior knowledge encoded by an LLM). |
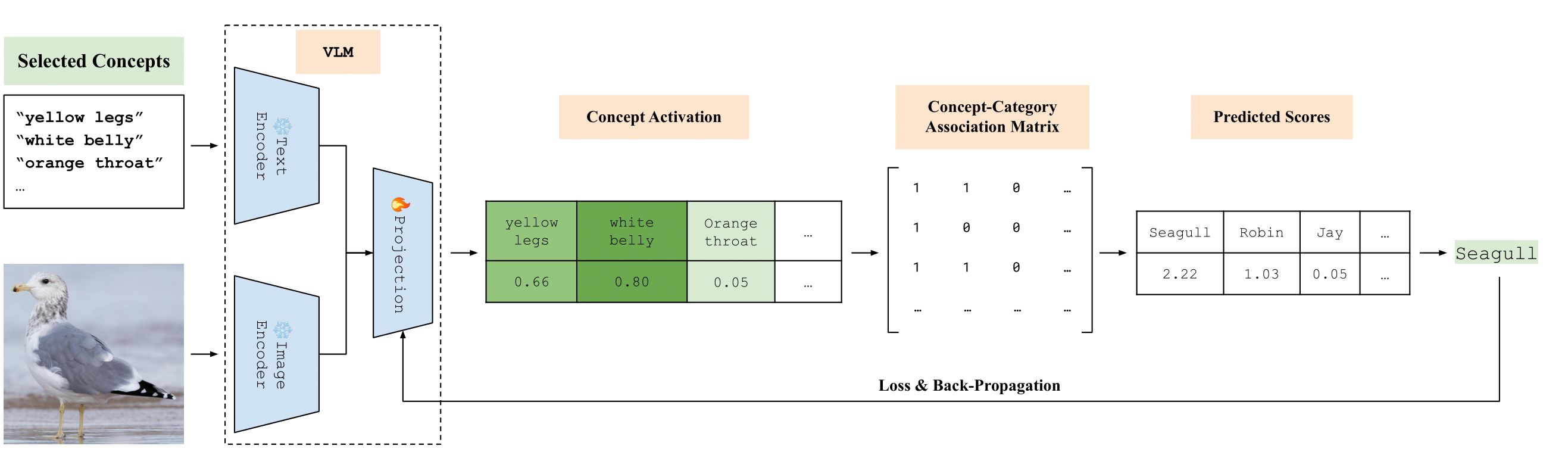 |
| We assume that the vision-language pre-training learns powerful encoders for recognizing visual concepts, but visual concept recognition can be further improved by ``re-aligning'' the image-text interface. Hence, we propose a self-supervised concept learning framework. We construct a fixed concept-category association matrix with the help of the LLM. We then fine-tune only the linear projection layers of the VLM through the concept bottleneck, by asking it to justify its own prediction: Namely, the classification objective is obtained by asking the VLM to perform zero-shot object classification. |
| We evaluate the proposed concept discovery method by building Concept Bottleneck Models for image classification tasks, comparing with previous works LaBo and LM4CV. We also evaluate the quality of concepts discovered and learned by the proposed CDL framework. |
| 1. Concept-based Image Classification |
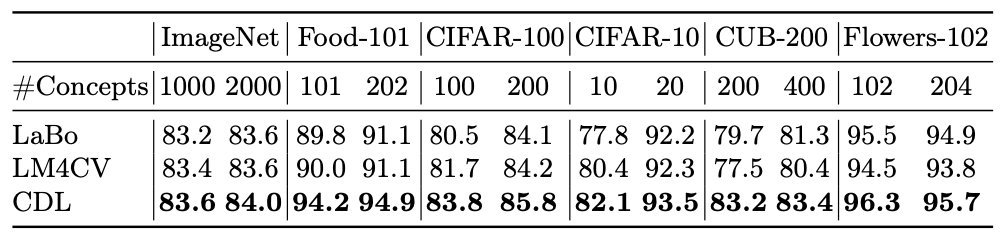 |
| Our concept discovery method consistently outperforms the baseline methods on all datasets with the same concept bottleneck sizes. |
| 2. Evaluation of the Discovered and Learned Concepts |
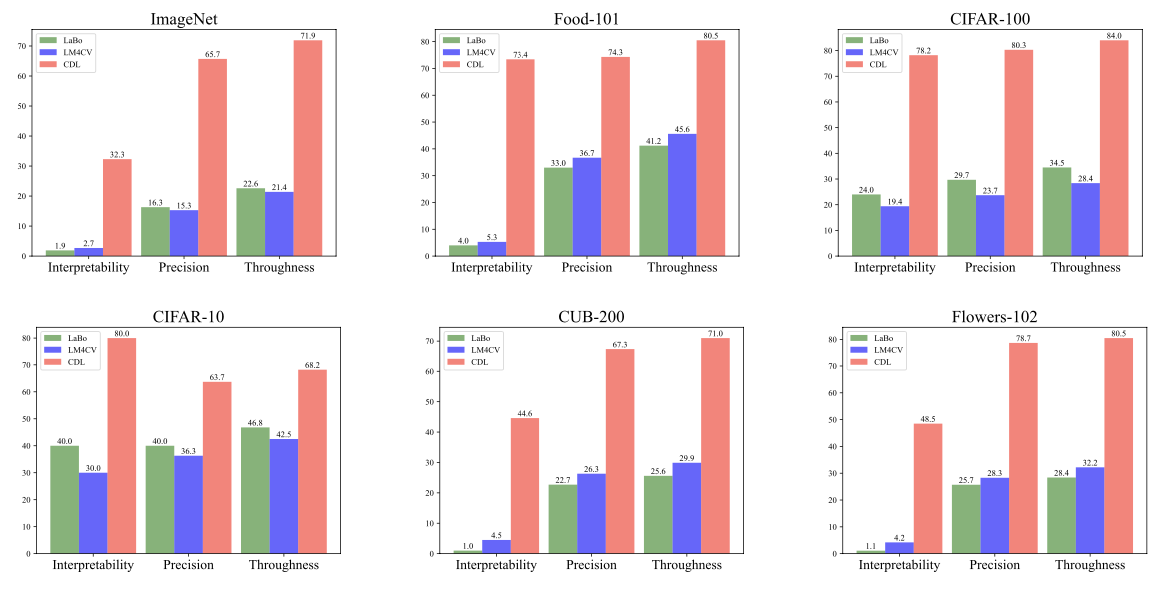 |
| We perform automatic and human evaluation to measure the interpretability, precision and thoroughness of the discovered and learned concepts in our framework. The results show that our CDL framework provides significant improvements on the quality of concepts. The consistently high quality of the discovered and learned concepts also suggests that VLMs do learn visual concepts during pre-training. |
 |
 |
 |
 |
Yuan Zang, Tian Yun, Hao Tan, Trung Bui, Chen Sun. Pre-trained Vision-Language Models Learn Discoverable Concepts arXiv |
|
AcknowledgementsThis template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here. |